Evaluation Metrics 101



Model Performance Metrics
The answer to the question above is quite simple. You test the model with questions, to which you already know the answers. Then you arrive at a number that is meaningful for the task that your model is performing. Depending on the context you may want this number to be higher or lower. Where do you get these queries and corresponding ground truths? You just refrain from training on some of the training samples and use them for testing. Once you keep some samples away for testing you absolutely cannot snoop this data. Data Leakage is a nasty result of snooping the test set, which many beginner ML practitioners won't even notice.
 |
| I tested this model using training data. I should be fine right? |
Let's talk about robust testing data procurement another day. Let's say we found some irrefutable test data and throwed it into the model and got some answers. We compared these answers to the ground truths and calculated an evaluation metric. Now several questions pop up in our heads, what is this metric? How do you use this metric? How do you choose a metric? etc. This metric can be a very simple and intuitive metric that you can explain to business people or an obnoxiously complex one that only your Data Science brethren can understand. In this post let's start exploring the basic metrics used for classification and then move on to more arcane ones.
Classification
I will not get into rigorous details of classification but let's just informally define classification.
Classification is the act of classifying your input into predetermined groups or categories or classes.
Examples:
- Given an image you might want to classify whether it contains a dog or cat.
- Given a comment we need to assess if they liked the movie.
- Given a Book title we might want to guess the publication.
- Given the court room proceedings we want to predict if the accused is found guilty?
Let's use the last example as an analogy through out the article.
Accuracy
Accuracy is a metric that measures how accurate your model is. No shit, Sherlock. But what does accurate mean? Well it depends on the context but one of the most used version is the average number of times your prediction is correct.

Now when I say my guilt prediction model has 80% accuracy that means 80% of the time my model's output is correct. Our Model is evaluated just like that. problem solved right? No. To find out why let's look at something called a confusion matrix.
 |
| Confusion Matrix of the test predictions |
Confusion matrix shown above should be self explanatory. We can see that the model actually gave up on the prediction task and always says that the accused are not guilty. But the accuracy is still 80% and is quite a good number and propitious enough to push it into production. The model here is just dumb.

Code
Precision;
Precision or Specificity is a decent metric which is almost as explainable as accuracy. Precision unlike accuracy is defined for each of the predetermined classes or categories. It's up to us to aggregate them in whatever way we want. We can even present them as is, as the individual precision of classes contain more information. So how do we calculate this wonderful precision.
In case of Binary classification like our guilty criminal prediction model we usually generate precision of the positive class as generally positive case is more important.
We can interpret precision as the degree of belief, when our model says that accused is guilty. It is the probability that the accused is actually guilty.
Precision despite being a good metric is not the be all and end all metric. High precision systems can be dumb too .Following confusion matrix shows one such scenario.
 |
| Dumb Yet High Precision predictions |
It is better that ten guilty persons escape than that one innocent suffer.
High precision is necessary, but not sufficient for a good model.
High precision is necessary, but not sufficient for a good model.
Code
Recall
The problem with precision is that, it does not consider how many guilty criminals are vindicated.
Recall or Sensitivity is a metric that actually cares about this a lot. Recall is the number of accused predicted guilty out of all guilty persons. It is the percentage of the actually guilty people that are convicted by the model.
As you would have already guessed it high recall systems can be dumb too. Model just needs to say that every accused is guilty to get high recall.
 |
| Dumb Yet high recall Predictions |
This model is just like this guy

Code
F1 Score
We can see that precision and recall are complementary in their model evaluation approaches, if we can find a balance between the two then that will be our perfect metric.F1 score is the harmonic mean of precision and recall. The following visualization by pavan mirla can explain F1 score in an interactive way.
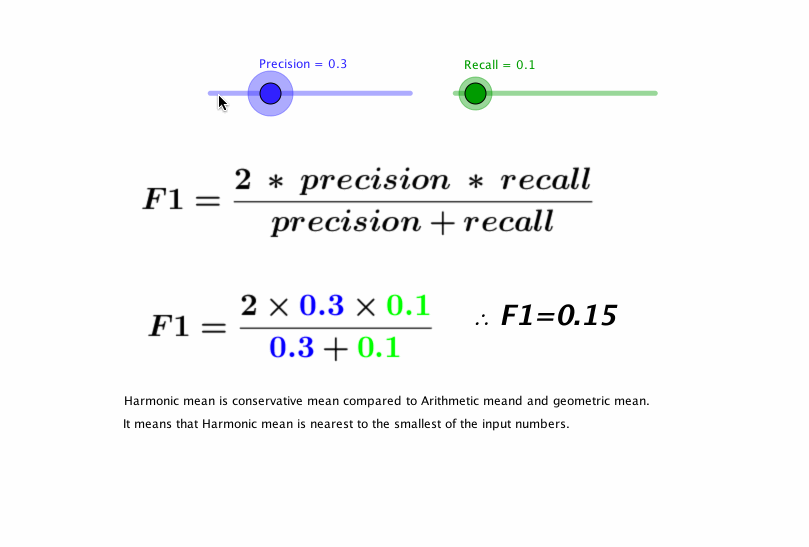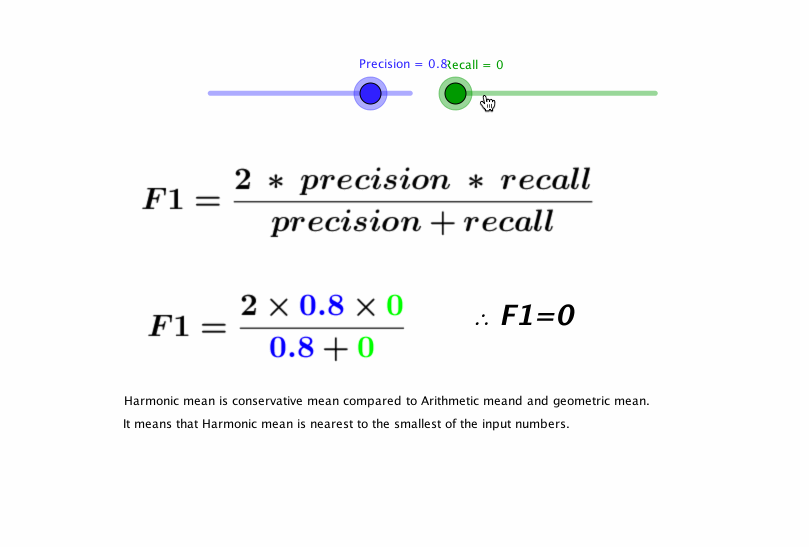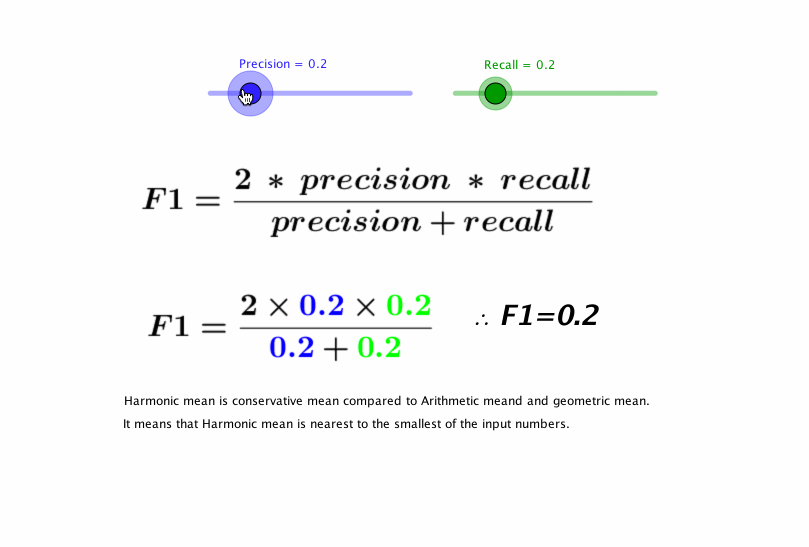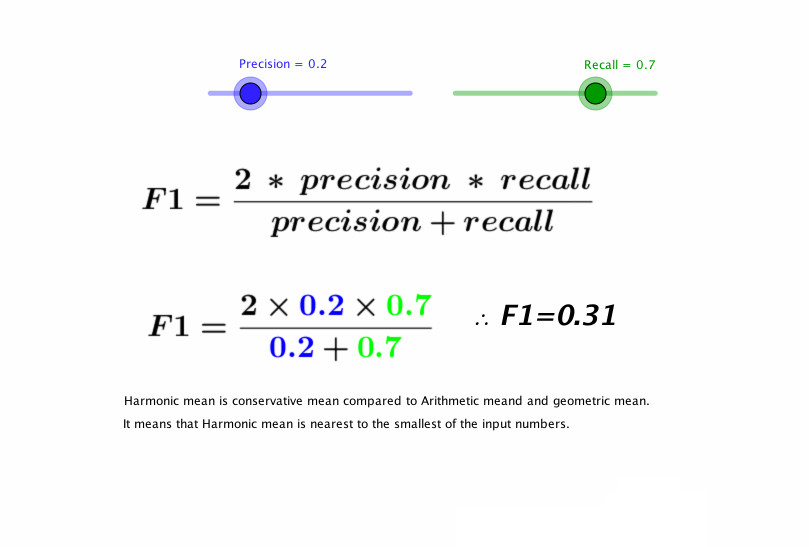
F1 Score seems to be a perfect metric for evaluating binary classification models, In fact, it is too perfect. Several Use cases of classification require the evaluating metric to be biased.F1 score does not care about the distribution of wrong predictions in classes.
Example: If we are using a model to classify a tumor, we may need the model to be more precise about fatal malignant tumors, while we are lenient about some benign tumors being misclassified. F1 score won't be able to handle such requirements.
Code
Conclusion
There are more such metrics like weighted F1 score, weighted relative accuracy etc.
It is the responsibility of the ML Practitioner to choose the correct metric after considering the requirements of task, type of the data and the implications of using one metric over another.

Comments
Post a Comment