Categorical Cross Entropy loss vs Sparse Categorical Cross Entropy loss vs Kullback-Leibler Divergence loss


Introduction
How would we say if a model is good or bad?
We need a measure of performance to assess the model. This measure based on the context is either minimized or maximized to optimize the model. A measure which is minimized to optimize the model is called “Loss”. Several factors like type of the data, learning algorithm used etc. come into play when choosing a Loss function. In this post let’s explore a few Loss functions which are based on Entropy.
Cross entropy
Entropy is the measure of “uncertainty” in the possible outcome of random variables.
In the context of classification If all the classes are equally probable then the system is of high entropy and vice versa. It is mathematically given as
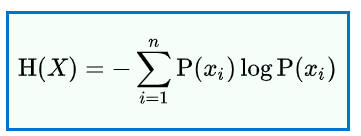
What does this entropy mean in terms of assessment of a model performance. Let’s understand this with the help of the infamous CIFAR 10 dataset.
This Data set contains tons of images belonging to 10 mutually exclusive classes. Here’s an example-

Unique classes in Dataset [frog, truck, deer, automobile, bird, horse, ship, cat, dog, airplane]
Let’s compare 2 models trained to detect classes given images using. Activation function final layer is SoftMax as we need the inputs to entropy calculation to be probability distributions.

Entropy of Model X’s prediction is 0.045
Entropy of Model Y’s prediction is 0.0043
We can see from the predictions that Model Y’s prediction is better as it is more certain about the result. This can be seen by comparing entropies also.
We can think of entropy as the opposite of information. Lower the entropy higher the information in the prediction. More information in the prediction means that the model is confident.
But certainty alone cannot decide whether a prediction is good or bad. Given the true labels we also need to check if it is correct or not. In other words we need to know information present in predicted probabilities according to the true probabilities. This is what Cross Entropy does. It takes into consideration the correctness of a prediction and gives a measure.
Cross Entropy is mathematically given as

Here p represents the true probabilities of each class for a data point.
q represents the predicted probabilities of each class for a data point.
Ep[.] represents expected value operator with respect to distribution p. One way to think about H(p,q) is the entropy or (~)information in q according to p.
If p = [p1,p2,p2……….pC] and q=[q1,q2,q2……….qC], then
H(p,q)=-(1/C)t=1Cptlog(qt)
p=[1{y=1}, 1{y=2}, 1{y=3} ,.....1{y=C}] 1{condition} = 1 if condition is True else 0.

Now let us look at predictions for a different image. If we look at entropy Model y is better but cross entropy uses probabilities and gives less for Model X.
In case of Mutually Exclusive labels(Multiclass Classification) only one entry in the true probability vector is non zero.
Intuitively this makes sense as minimizing cross entropy means maximizing the predicted probability for the ground truth class.
Cross Entropy generalizes to the case of non mutually exclusive labels as well.
If the number of classes is 2 Then this measure is called binary cross entropy loss else if the number of classes is more than 2 then it is called categorical cross entropy.
Now that we know what cross entropy means let's move forward and compare it with Sparse Categorical Cross Entropy.
Categorical Cross Entropy vs Sparse categorical Cross Entropy
Categorical and Sparse cross entropies differ mostly in the way they are implemented.
Categorical cross entropy needs the true label to be a vector of probabilities.
Sparse categorical Cross entropy needs ground truth to be encoded as a single value.
Sparse Categorical Cross Entropy H(y,q) = -log(qt)
when y=t
here y is the true label
There is a catch with the Sparse version of Categorical Cross Entropy. It only cares about the class with highest probability(pi).This may not seem like a problem in the context of Multiclass Classification such as the current example, But this makes it a bad Measure in case of Multilabel Classification where one image might contain both dog and cat.
The Advantage of the Sparse version is that it is much more efficient as logarithm is calculated only once per data point. It also saves space as it doesn’t need the categories to be one hot encoded.
Kullback-Leibler Divergence
In many machine learning tasks we need to compare two distributions. This can be done using several distance measures depending on the use case.
In some cases we want this distance to be asymmetric. We want to measure how different a distribution is from another. Say we need to find how much the predicted probability distribution differs from original probability distribution. Such distances are called Divergence.
KL Divergence is a very popular divergence measure of how much one probability distribution is different from a second. It has applications in VAE, variational inference of posteriors etc.. Mathematical Expression of KL Divergence is
Dk.L(p|q) = -(1/C)t=1Cptlog(qt/pt)
From simple manipulations it can be obtained that
Dk.L(p|q) = H(p,q) - H(p,p)
This intuitively means that KL Divergence is the information lost or entropy gained if we approximate p with q. In case of prediction task this is a good measure of loss.
Entropy of p is constant because it is given by the observed data. Minimizing KL Divergence boils down to minimizing Cross entropy.
During Multiclass Classification Entropy of p is zero as one data point can only be mapped to a single class, the summation of weighted log probabilities becomes zero. This makes KL Divergence equivalent to Cross Entropy in the final result.
Sparse Categorical Cross Entropy is the efficient loss in this case for the same reasons mentioned above when comparing it with Categorical Cross Entropy
Difference arises during Multilabel Classification when entropy of p is not zero. In this case KL Divergence is a more complete measure of performance of model as it does not have entropy of true label as an artefact.
Code

Like we discussed above we need to encode true labels as one hot vectors in order to apply Categorical Cross Entropy as the objective function.
Let’s build a basic CNN Model with some BN and dropout layers

Note that we used SoftMax as activation layer since we needed the inputs for loss calculation to be probability distributions.
Time to choose the loss function. Code below shows how to choose Categorical Cross Entropy as loss function.

Model is optimized by minimizing categorical cross entropy but the metrics provided are also logged. Let’s checkout the results.
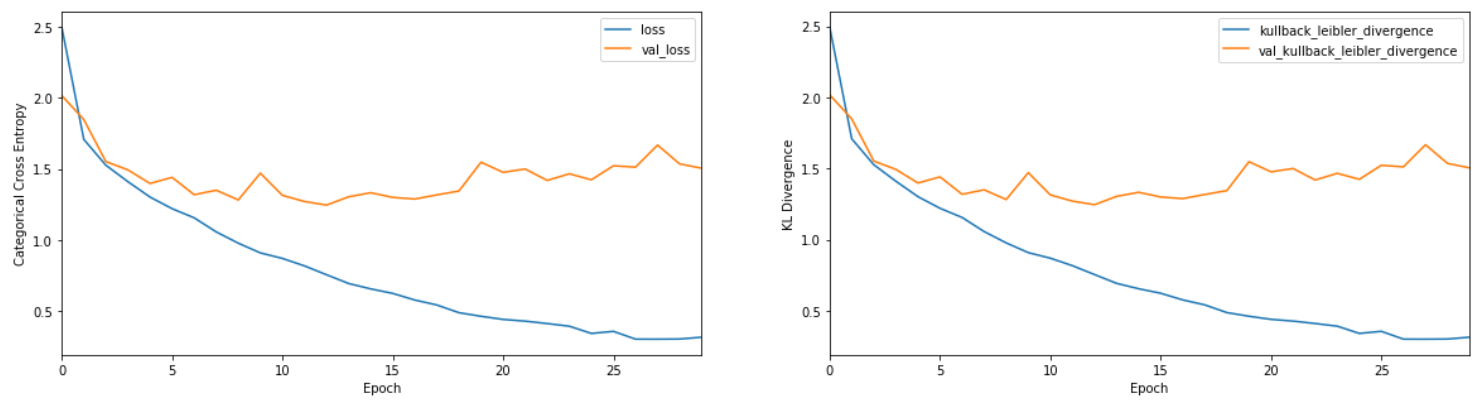
KL Divergence and Categorical Cross entropy are exactly the same. This is because our classes are mutually exclusive.
Let’s see what choosing Sparse Categorical Cross Entropy gives

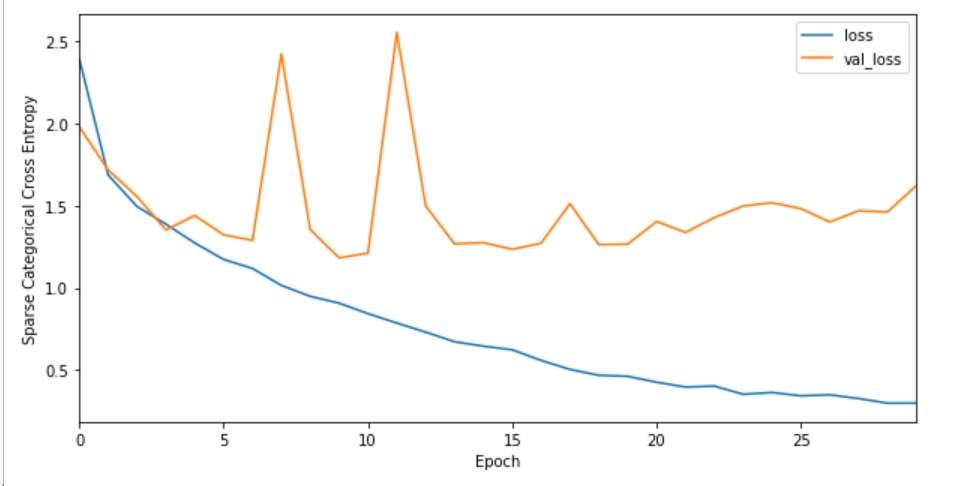
Sparse Categorical Cross Entropy is mostly the same as Categorical Cross Entropy(differences are due to the splitting of data b/w train and validation sets)
Using KL Divergence as the loss function:

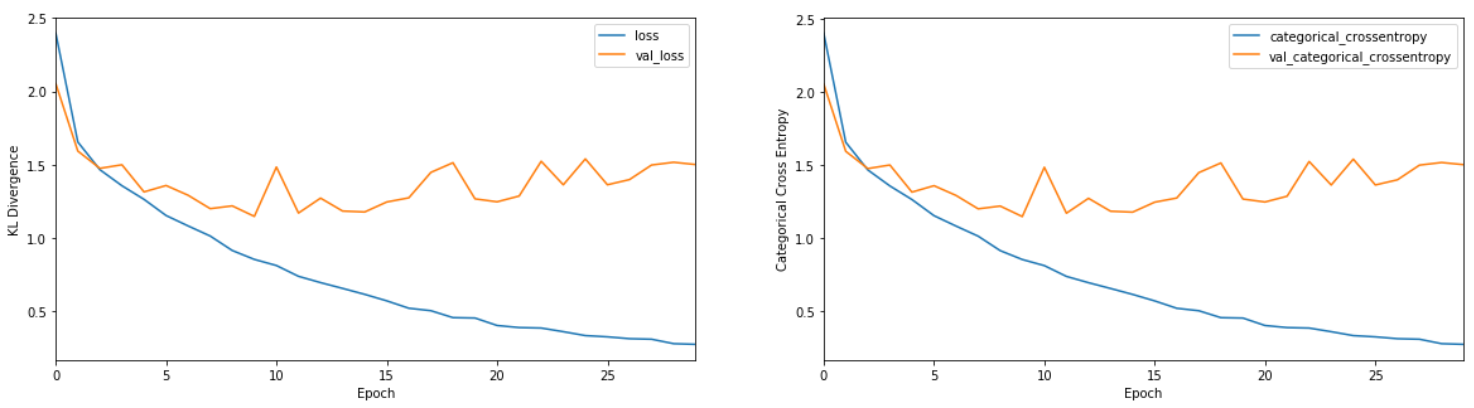
K.L Divergence is also the same as categorical cross entropy for this classification task.
These losses are available in tensorflow’s API for Keras under the following names.
tf.keras.losses.CategoricalCrossentropy()
tf.keras.losses.SparseCategoricalCrossentropy()
tf.keras.losses.KLDivergence()
Gist
All the three losses discussed are theoretically very different but in tasks like Multiclass Classification they are essentially the same. Following is the summary of things discussed in the post.

Comments
Post a Comment